

中国计算机学会青年计算机科技论坛
CCF Young Computer Scientists & Engineers Forum
CCF YOCSEF
于2016年6月24日(星期五) 9:30-12:30
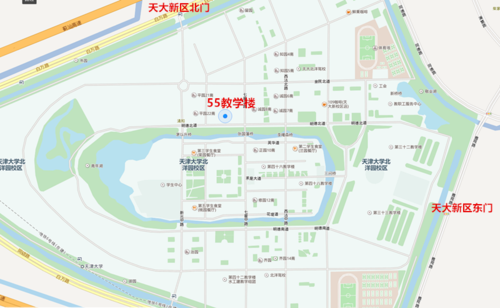
在天津大学北洋园校区计算机学院(55教学楼B-202)
报告会主题
知识图谱的技术新进展
程 序
09:00 签到
09:30 报告会开始
特邀讲者:王克文 博士,澳大利亚格里菲斯大学 教授
报告题目:本体和知识图谱中的非标准推理
特邀讲者:漆桂林 博士,东南大学 教授
报告题目:知识图谱中推理技术及其在高考机器人中的应用
特邀讲者:鲍 捷 博士,文因互联(Memect)创始人兼CEO
报告题目:模型论,语义信息论和词嵌入
执行主席:张小旺 博士,天津大学 副教授,CCF YOCSEF天津委员
如参会,请于6月22日前邮件回复,以便提供会务。
联系方式:张小旺,xiaowangzhang@tju.edu.cn
联系地址:天津市海河教育园区雅观路135号天津大学北洋园校区55教学楼B405
乘车路线:613(华山里地铁站),615 (天津大学卫津路校区),216(复兴门地址站)
校内通勤车(从天大新区东门口到55教学楼)
特邀讲者:王克文
 王克文博士是格里菲斯大学计算机与信息学院的教授,是该校人工智能与语义技术实验室(AIST)的主任。他于1996年在南开大学数学研究所获得理论计算机科学方向的博士学位(首批硕士直攻博),1996-1999在国防科大和香港科大从事博士后研究,1999-2002任清华大学计算机系副教授(并在2000-2002兼任德国波茨坦大学计算机系研究员),2002起在格里菲斯大学任职。他的研究兴趣包括人工智能(知识表示,逻辑程序设计,智能体),计算逻辑,语义网理论和技术。他一直在人工智能的顶级会议和杂志发表文章(比如AAAI, IJCAI, Artificial Intelligence, ACM Transactions on Computational Logic, Theory and Practice of Logic Programming等),近年来一直是相关顶级会议的程序委员会委员或高级委员。他也是语义技术方面的著名杂志Journal of Web Semantics的编委会成员。
王克文博士是格里菲斯大学计算机与信息学院的教授,是该校人工智能与语义技术实验室(AIST)的主任。他于1996年在南开大学数学研究所获得理论计算机科学方向的博士学位(首批硕士直攻博),1996-1999在国防科大和香港科大从事博士后研究,1999-2002任清华大学计算机系副教授(并在2000-2002兼任德国波茨坦大学计算机系研究员),2002起在格里菲斯大学任职。他的研究兴趣包括人工智能(知识表示,逻辑程序设计,智能体),计算逻辑,语义网理论和技术。他一直在人工智能的顶级会议和杂志发表文章(比如AAAI, IJCAI, Artificial Intelligence, ACM Transactions on Computational Logic, Theory and Practice of Logic Programming等),近年来一直是相关顶级会议的程序委员会委员或高级委员。他也是语义技术方面的著名杂志Journal of Web Semantics的编委会成员。
报告提要:基于本体的知识库已经广泛应用于智能万维网搜索,查询理解,上下文广告,社交媒体和生物医学等领域。比如谷歌的知识图谱就是一个重要的例子,其中语义信息的使用大大加强了搜索引擎的准确性。在实际应用中,现代知识库需要处理大规模动态的数据,表示复杂的知识,并能快速更新。W3C 的OWL语言(Web Ontology Language)为解决现代知识库的这类问题提供了契机,并且各种高效的推理系统已经或正在开发。已有的方法和系统大都关注于基本的推理机制,但一些更高级的推理机制,比如查询解释,本体修正,模块化,归纳推理,和非单调推理等,还没有受到足够的重视,也缺少相应的高效推理系统。在这个报告中,我们简要介绍这方面的公开问题,最新进展,以及我们的工作。
特邀讲者:漆桂林

漆桂林博士是东南大学教授、博导,担任中国中文信息学会语言与知识计算专业委员会副主任和中国计算机学会中文信息技术专业委员会专委委员。他于2002年从江西师范大学获得基础数学硕士学位,2006 年从英国贝尔法斯特女皇大学获得计算机科学博士学位,师从人工智能界著名专家Weiru Liu教授。2006 年8 月至2009 年8 月,在德国Karlsruhe 大学AIFB 研究所做博士后研究,师从语义Web界国际知名专家Rudi Studer教授。他担任Journal of Web Semantics的编委。他多次担任AAAI人工智能会议(AAAI)、国际联合人工智能会议(IJCAI) 、万维网大会(WWW)、国际语义Web会议等会议的程序委员,并担任过中国语义Web和Web科学联合会议主席(CSWS2012)等职务。先后承担包括国家自然科学基金和欧盟第七框架项目Marie Curie IRSES在内的多项科研项目。他负责了百度合作项目“本体及知件技术构建医疗领域知识库和应用研究”,并且作为第二负责人参与了由科大讯飞牵头的863课题“高考机器人”的一个子课题。在知识工程、大数据语义分析、知识图谱等领域有将近20年的研究。参与开发了著名的开源多平台本体编辑工具NeON Toolkit,开发了多个知识推理系统。开发了一个基于语义技术的问答式企业数据库智能搜索引擎。申请发明专利4项,获得一项软件著作权。
报告提要:知识图谱的概念由谷歌2012年正式提出,旨在实现更智能的搜索引擎,2013年以后开始在学术界和业界普及,并在智能问答,医疗,反欺诈等应用中发挥重要作用。随着知识图谱的研究的深入,研究人员发现知识图谱在应用中存在以下质量问题:第一个问题知识图谱的不完备性,即知识图谱中有些关系会缺失;第二个问题是知识图谱中存在错误的关系。为了解决这两个问题,就要求对知识图谱的推理进行研究。知识库推理可以粗略地分为基于符号的推理和基于统计的推理。在人工智能的研究中,基于符号的推理一般是基于经典逻辑(一阶谓词逻辑或者命题逻辑)或者经典逻辑的变异(比如说缺省逻辑)。基于符号的推理可以从一个已有的知识图谱推理出新的实体间关系,从而有助于解决第一个问题,而且基于符号的推理可以对知识图谱进行逻辑的冲突检测,从而有助于解决第二个问题。基于统计的方法一般指机器学习方法,通过统计规律从知识图谱中学习到新的实体间关系,从而处理第一个问题;并且对新学到的关系进行评分,从而去掉那些可能错误的关系,从而处理第二个问题。
本次报告旨在全面介绍知识图谱推理技术最新进展。报告内容覆盖:
1) 介绍知识图谱中知识表示和推理的背景
2) 介绍基于本体和规则的知识推理技术和一些大规模推理工具
3) 介绍基于统计的知识推理技术
4) 讨论知识库推理在863高考机器人解题中的应用
5) 给出知识推理未来发展的一些建议
特邀讲者:鲍 捷
 鲍捷博士是文因互联(Memect)创始人兼CEO,中文信息学会语言与知识计算专委会委员,W3C顾问委员会代表。他是前三星美国研究院研究员,MIT访问研究员,RPI博士后,Iowa State Univ博士。他是三星S-Voice个人助手核心设计者,也是语义网基础国际标准OWL2的作者之一,W3C Web本体语言工作组成员。在语义网、知识图谱、机器学习、神经网络等领域发表过70多篇论文。
鲍捷博士是文因互联(Memect)创始人兼CEO,中文信息学会语言与知识计算专委会委员,W3C顾问委员会代表。他是前三星美国研究院研究员,MIT访问研究员,RPI博士后,Iowa State Univ博士。他是三星S-Voice个人助手核心设计者,也是语义网基础国际标准OWL2的作者之一,W3C Web本体语言工作组成员。在语义网、知识图谱、机器学习、神经网络等领域发表过70多篇论文。
报告提要:何为符号的语义?如何在数学上精确地刻画语义,以及在工程中以有限的成本近似地表达语义?逻辑、信息论、分布式表示从不同的角度来解决这个问题。在这个讲座中我们探讨这三个领域之间的关系。1)在逻辑中,我们用“模型”(model)来赋予表达式精确的语义。在概率逻辑中,模型本身被关联以概率分布,表达式之间存在概率一致性的约束。2)经典信息论仅衡量符号本身的语法熵。如果我们考虑符号之间的推理关系,则扩展经典信息论为语义信息论。经典信息论研究消息自身出现的概率及其语法形式在通讯中的保真,而语义信息论研究消息为“真”的概率及其真伪在通讯中的保真(语法表达本身可以改变)。我们以概率模型论作为语义信息论的数学基础,介绍语义信源和信道编码的两个核心定理。3)但严格的基于概率模型论的语义信息论在工程上是难以计算的。我们发现基于概率命题逻辑的语义信息,和基于分布式表示的词嵌入模型,有明显的对应关系。因而,词嵌入模型如word2vec可以看作语义信息的近似。我们展望基于张量方法的分布式表示也许可以视为概率一阶逻辑及其语义信息的近似。
执行主席:张小旺
 张小旺博士是天津市青年千人、天津大学计算机学院副教授,担任天津市认知计算与应用重点实验室副主任、CCF YOCSEF天津委员、中国中文信息学会语言与知识计算专业委员会委员。 2011年于北京大学获得博士学位,2014年于比利时哈瑟尔特大学博士后出站。主要研究方向为:人工智能、数据库与知识图谱。研究兴趣包括:本体推理、图数据库、异构数据库、SPARQL等。目前主持国家自然科学基金项目1项,参与的项目有:比利时国家FWO项目、澳大利亚国家ARC项目、国家自然科学基金(重大)项目等课题。在国际期刊Journal of Artificial Intelligence Research,The Computer Journal,International Journal of Approximate Reasoning等国际会议ESWC、ICDT、ECAI等上发表论文30多篇;担任多份国内外期刊和会议审稿人。
张小旺博士是天津市青年千人、天津大学计算机学院副教授,担任天津市认知计算与应用重点实验室副主任、CCF YOCSEF天津委员、中国中文信息学会语言与知识计算专业委员会委员。 2011年于北京大学获得博士学位,2014年于比利时哈瑟尔特大学博士后出站。主要研究方向为:人工智能、数据库与知识图谱。研究兴趣包括:本体推理、图数据库、异构数据库、SPARQL等。目前主持国家自然科学基金项目1项,参与的项目有:比利时国家FWO项目、澳大利亚国家ARC项目、国家自然科学基金(重大)项目等课题。在国际期刊Journal of Artificial Intelligence Research,The Computer Journal,International Journal of Approximate Reasoning等国际会议ESWC、ICDT、ECAI等上发表论文30多篇;担任多份国内外期刊和会议审稿人。
校园地图